Python - Extended Sequence Unpacking in Python 3.X
Introduction
Sequence assignments normally require exactly as many names in the target on the left as there are items in the subject on the right.
We get an error if the lengths disagree in both 2.X and 3.X unless we manually sliced on the right:
Demo
seq = [1, 2, 3, 4] a, b, c, d = seq # w w w. j a v a 2s .co m print(a, b, c, d) #a, b = seq #ValueError: too many values to unpack (expected 2)
Result
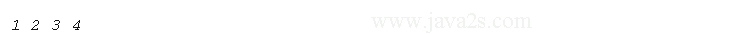
In Python 3.X, we can use a single starred name in the target to match more generally.
In the following code, variable a matches the first item in the sequence, and b matches the rest:
Demo
seq = [1, 2, 3, 4] a, *b = seq # from w w w . j av a 2 s. c om print( a ) print( b )
Result
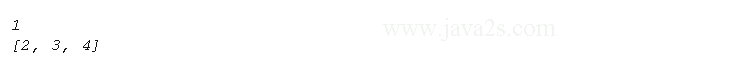
The starred name can appear anywhere in the target.
For instance, in the next interaction b matches the last item in the sequence, and a matches everything before the last:
Demo
seq = [1, 2, 3, 4] *a, b = seq # ww w. j av a2 s . c om print( a ) print( b )
Result

When the starred name appears in the middle, it collects everything between the other names listed.
In the following interaction a and c are assigned the first and last items, and b gets everything in between them:
Demo
seq = [1, 2, 3, 4] a, *b, c = seq # from w w w . ja v a 2s .c om print( a ) print( b ) print( c )
Result

Wherever the starred name shows up, it will be assigned a list that collects every unassigned name at that position:
Demo
seq = [1, 2, 3, 4] a, b, *c = seq # w w w . j av a 2 s .c om print( a ) print( b ) print( c )
Result

Like normal sequence assignment, extended sequence unpacking syntax works for any sequence types and any iterable, not just lists.
Demo
a, *b = 'test' print( a, b )# from w ww. j av a2 s.c o m a, *b, c = 'test' print( a, b, c ) a, *b, c = range(4) print( a, b, c )
Result

We don't have to manually slice to get the first and rest of the items:
Demo
L = [1, 2, 3, 4] while L: # from w ww . j ava 2s .c o m front, *L = L # Get first, rest without slicing print(front, L)
Result

Related Topic
- Sequence Assignments
- Assignment Unpacking * syntax
- Sequence-unpacking assignments
- Boundary cases for Extended Sequence Unpacking