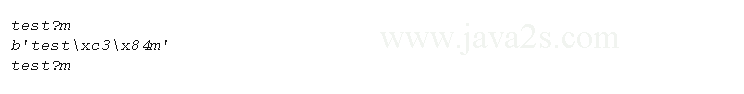Python - Python 2.X Unicode strings file
Introduction
In Python 2.X, Unicode strings are coded and display with a leading "u," byte.
And strings don't require or show a leading "b,".
Unicode text files must be opened with codecs.open, which accepts an encoding name just like 3.X's open.
Uses the special unicode string to represent content in memory.
Binary file mode may seem optional in 2.X since normal files are just byte-based data, but it's required to avoid changing line ends if present:
Demo
import codecs print( codecs.open('unidata.txt', encoding='utf8').read() ) # 2.X: read/decode text print( open('unidata.txt', 'rb').read() ) # 2.X: read raw bytes print( open('unidata.txt').read() ) # 2.X: raw/undecoded too # w w w.j av a2 s .c o m
Result