Python - Data Type Unicode Strings
Introduction
Python's strings have full Unicode support.
In Python 3.X, the normal str string handles Unicode text.
A distinct bytes string type represents raw byte values.
Demo
S = 'sp\xc4m' # 3.X: normal str strings are Unicode text print(S)# w w w . jav a 2 s . c o m print( b'a\x01c' ) # bytes strings are byte-based data print( u'test\u00c4m' ) # The 2.X Unicode literal works in 3.3+: just str
Result

In Python 2.X, the normal str string handles both 8-bit character strings (including ASCII text) and raw byte values.
A distinct unicode string type represents Unicode text.
3.X bytes literals are supported in 2.6 and later for 3.X compatibility and they are treated the same as normal 2.X str strings:
Demo
print(u'sp\xc4m') # 2.X: Unicode strings are a distinct type print( 'a\x01c' ) # Normal str strings contain byte-based text/data print( b'a\x01c' ) # The 3.X bytes literal works in 2.6+: just str # w ww. ja v a 2 s . co m
Result

In both 2.X and 3.X, non-Unicode strings are sequences of 8-bit bytes that print with ASCII characters when possible.
Unicode strings are sequences of Unicode code points-identifying numbers for characters.
Demo
print( 'test' ) # Characters may be 1, 2, or 4 bytes in memory print( 'test'.encode('utf8') ) # Encoded to 4 bytes in UTF-8 in files print( 'test'.encode('utf16') ) # But encoded to 10 bytes in UTF-16 # ww w . j a va 2s. c o m
Result

Both 3.X and 2.X also support the bytearray string type.
bytearray string type is essentially a bytes string (a str in 2.X) that supports most of the list object's in-place mutable change operations.
Both 3.X and 2.X support coding non-ASCII characters with \x hexadecimal and short \u and long \U Unicode escapes.
Python also handles file-wide encodings declared in program source files.
Here's our non-ASCII character coded three ways in 3.X (add a leading "u" and say "print" to see the same in 2.X):
Demo
print( 'test\xc4\u00c4\U000000c4m' ) print( '\u00A3', '\u00A3'.encode('latin1'), b'\xA3'.decode('latin1') )
Result
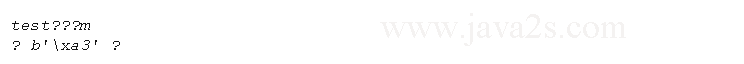
Python 2.X allows its normal and Unicode strings to be mixed in expressions as long as the normal string is all ASCII.
Python 3.X has a tighter model that never allows its normal and byte strings to mix without explicit conversion:
u'x' + b'y' # Works in 2.X (where b is optional and ignored) u'x' + 'y' # Works in 2.X: u'xy' u'x' + b'y' # Fails in 3.3 (where u is optional and ignored) u'x' + 'y' # Works in 3.3: 'xy' 'x' + b'y'.decode() # Works in 3.X if decode bytes to str: 'xy' 'x'.encode() + b'y' # Works in 3.X if encode str to bytes: b'xy'
Related Topic
- Strings
- String concatenation
- String Immutability
- String Methods
- String escape
- Multi line string
- Raw string
- String Pattern Matching
- String Sequence Operations
- Step across the characters in a string, printing the uppercase version of each as it goes: